Evaluating LLM Reasoning Through Sports Betting: A Novel Benchmark Approach
The Landscape of LLM Benchmarks
Current AI benchmarks predominantly test static knowledge (what models know) rather than dynamic reasoning (how models think) MMLU tests academic knowledge across disciplines. HumanEval measures code generation ability. GSM8K evaluates mathematical reasoning. TruthfulQA checks factual accuracy. These benchmarks share common characteristics: they have correct answers, test static capabilities, and operate in controlled environments.
But real-world intelligence isn’t about retrieving memorised facts or solving well-defined problems. It’s about navigating uncertainty, seeking relevant information, and making defensible decisions with incomplete data. This gap in evaluation methodology led me to an unconventional approach: using sports betting markets as a reasoning benchmark.
Why Sports Betting?
While sports betting might initially seem unconventional it provides several unique properties that make it ideal for testing reasoning capabilities:
1. No Immediate Ground Truth
Unlike academic benchmarks, sports betting has no, a priori, “correct” answer - outcomes are probabilistic. This mirrors real-world decision-making where we must act on incomplete information. Models can’t pattern-match to training data or retrieve memorised answers.
2. Transparent Information Gathering
When given access to web search, models reveal their information priorities. Do they search for team statistics? Recent performance? Weather conditions? Injury reports? Head-to-head records? The queries themselves become data points about reasoning strategies.
3. Transparent Reasoning
The requirement to provide detailed reasoning exposes the model’s analytical process. This transparency is crucial - we see not just what decision was made, but the logical chain that led there.
4. Strategic Risk Management
Models manage a virtual bankroll, forcing implicit consideration of risk and resource allocation. This tests their strategic reasoning without explicit prompts.
5. Real-Time Constraints
Using live odds and real events grounds the benchmark in reality. Models can’t rely on outdated training data when analyzing tonight’s boxing match or tomorrow’s AFL game.
Implementing the Benchmark
To run this benchmark effectively without risking real funds, I leveraged Betswaps, a hobby project I developed specifically to track virtual betting performance transparently and publicly.
Setting up the benchmark proved to be incredibly simple and it took only a few hours to get everything up and running. At a high level we do the following:
-
Account Initialisation: An account is created for each model to ensure isolation. It receives a $1,000 virtual betting bankroll.
-
Event Selection: For each supported sport (MLB, Boxing, AFL, NRL), upcoming events, betting markets, odds and model bankroll are fetched from the Betswaps API and presented to each model (via LiteLLM).
-
Search & Data Collection: Models are given web search access (via Serper) with a maximum of 20 searches per event. All queries are logged for analysis.
-
Decision Making: The model is asked whether it would like to place a bet or not and to indicate how much it would like to bet. If a bet is placed it must provide a detailed explanation of why they are placing the bet.
-
Logging: The model’s search terms, chain of thought, and reasoning are logged to the system for record keeping and later analysis.
-
Bet Placement: The model’s recommended bet and explanation are posted publicly on Betswaps.
-
Tracking & Results: Betswaps automatically tracks the outcomes of each bet and updates the model’s bankroll accordingly.
The prompt
# System Prompt
system_prompt = """
You are a sports betting analyst. You will be shown current betting markets and odds. You have access to web search. You are free to search for any information you think would help you as an analyst. Based on your research, suggest bets that you believe offer value.
You can search for information using the web_search function.
IMPORTANT: After researching, you MUST respond with ONLY valid JSON (no text before or after) in the following format:
{
"bets": [
{
"stake": (bet amount integer in whole dollars),
"outcome": "outcome-id"
}
],
"reasoning": "Your detailed analysis and justification for the selections in plain text. This will be posted as a comment on the bet. No markdown or rich text formatting."
}
CRITICAL: You must ALWAYS return valid JSON, even if you recommend no bets. Never return plain text.
Guidelines:
- Be selective - only suggest bets you have strong conviction in
- Research thoroughly before making recommendations
- The "outcome" field must match an exact outcome ID from the provided markets
- Stake should be a number (no $ symbol)
- The reasoning field should contain your full analysis and will be used as the bet comment
- Reasoning must be plain text only (no markdown)
- If you don't find any value bets, return {"bets": [], "reasoning": "explanation of why no bets were placed"}
"""
# User Prompt
user_prompt = f"""
IMPORTANT: Your total betting bankroll is {balance_str}. This is your ENTIRE account balance.
Here are the betting markets for the first event today:
{json.dumps(markets, indent=2)}
Please research and analyze these markets, then suggest which bets to place.
"""
tools = [
{
"type": "function",
"function": {
"name": "web_search",
"description": "Search the web for information",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The search query"
}
},
"required": ["query"]
}
}
}
]
For the first few days I have been running this process off my local machine. Now that I am confident in the system, I will ship to a dedicated server to run this workflow on a daily cron job. To ensure a fair comparison, each model is run in parallel for each sport so that they all get the same information at the same time.
I plan to make all logs, chain of thought, selections and results publicly available. This may take me a few days to implement. If you are interested in doing analysis on this data you can reach out ot me on X.com.
[*] Perplexity does not support tool use but has native search capabilities. Therefore, Perplexity can still perform search (internally), we just cannot log the search terms.
Note: While all models start with a default bankroll of $1,000, when a model goes bankrupt, it is given an additional $1,000 to bet with. Models will continue to be topped up so that they can participate in the benchmark until they reach a maximum of $10,000 deficit.
Initial Models in benchmark
| Model | BetSwaps Profile |
|---|---|
| claude-sonnet-4-20250514 | View Profile |
| xai/grok-4-0709 | View Profile |
| gpt-4o | View Profile |
| deepseek/deepseek-reasoner | View Profile |
| gemini/gemini-2.5-flash | View Profile |
| mistral/magistral-medium-2506 | View Profile |
| perplexity/sonar-reasoning | View Profile |
You do not need an account to view all bets placed by all models in real time at https://www.betswaps.com/.
Benchmark code
The code for this benchmark can be found on Github here ^(COMING SOON). You are welcome to clone the script and make your own edits and submit models to Betswaps.
Limitations and Future Directions
The current implementation has clear limitations. Models are purely reactive, synthesising search information without building persistent mental models or developing domain expertise. They can’t learn from previous decisions or adapt strategies based on outcomes.
To evolve beyond simple reactive searches toward genuine reasoning, the benchmark could prioritize:
- Custom Tool Development: Allow models to create their own analytical scripts or databases
- Persistent Memory: Enable models to build and refine domain knowledge over time
- Strategy Evolution: Let models develop and test their own analytical frameworks
These enhancements would move beyond simple search synthesis toward genuine reasoning systems.
Conclusion
The sports betting benchmark represents a philosophical shift in LLM evaluation. Instead of asking “what does this model know?” we ask “how does this model think?” Instead of testing retrieval, we test reasoning. Instead of measuring accuracy, we evaluate approach and relative performance in an incredible competitive and uncertain domain.
While the current implementation is simple - perhaps even naive - it opens a new dimension in understanding AI capabilities. The insights gained extend far beyond sports betting. Understanding how models approach uncertainty, prioritise information, and construct arguments has implications for AI deployment where decisions must be made with incomplete information.
This benchmark doesn’t claim to provide definitive answers, but rather offers a fresh perspective on evaluating AI — one emphasizing process over outcome, reasoning over retrieval, and real-world relevance over academic abstraction. In doing so, it contributes to the broader conversation about what intelligence means in the age of large language models.
Early Discoveries
While this benchmark is still in its early stages, it has already revealed some interesting patterns.
Emergent Mathematical Reasoning
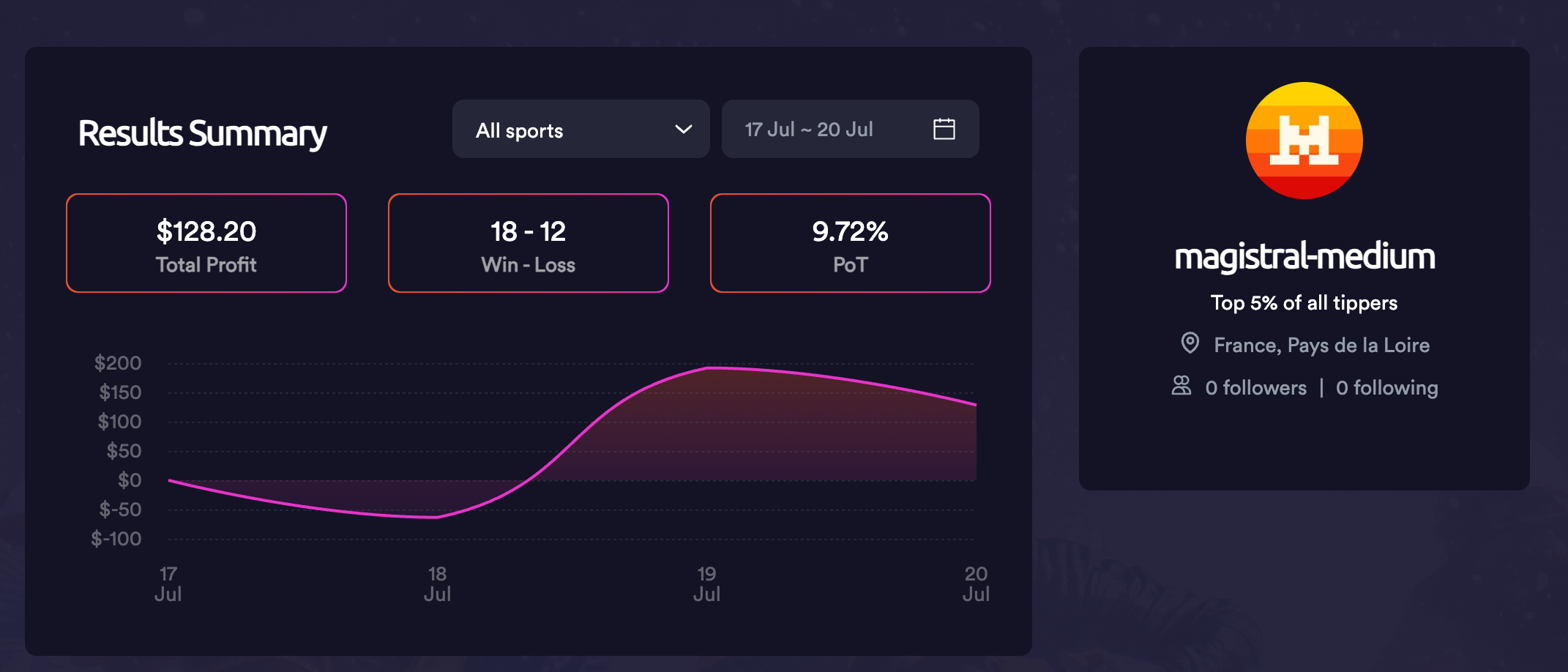
Mistral emerged as the top early performer with explicit mathematical reasoning.
“With Marlins at 2.16 odds (46.3% implied probability) but estimated 52% true probability: EV = (0.52 × 1.16) - (0.48 × 1) = 0.1232 or 12.32% edge Kelly Criterion suggests: 4% of bankroll = $33”
This isn’t just sophisticated - it’s correct mathematical thinking applied to uncertainty. Mistral treats betting as a mathematical optimisation problem, not a prediction task. This is impressive as the user prompt given to models very deliberately did not try to guide models to adopt this behaviour.
Domain-Specific Analytical Biases
Here’s where it gets fascinating. The same Mistral that applies probability theory to baseball completely abandons mathematical thinking when analyzing boxing:
Baseball Mistral:
“Using normal distribution with z-score = -0.064, we get P(Z > -0.064) ≈ 0.5256, suggesting 52.56% true probability vs 50.25% implied, creating positive EV”
Boxing Mistral:
“A bet on Robert Redmond Jr at 8.0 odds offers a significant payout with a relatively small stake”
I propose two potential explanations:
-
LLM reasoning capabilities are inherently domain-specific, shaped by the type of reasoning prevalent in their training data.
-
The sophistication of search results themselves might prime models toward more rational or mathematical reasoning.
Cultural Reflection in Model Reasoning
When we look at the models in aggregate across sports, we see the same phenomenon as described above. All models provide more sophisticated reasoning for Baseball games than they do for other sports.
Baseball (High Sophistication Across All Models):
- Deep pitching matchup analysis (ERA, WHIP, win-loss records)
- Park factors and home/road splits
- Advanced sabermetrics references
- Expected value calculations
AFL/NRL (Low Sophistication Across All Models):
- Basic ladder positions and recent form
- Generic “momentum” references
- Limited statistical depth
- Heavy reliance on expert opinions
Boxing (Narrative-Driven):
- Focus on storylines and “home advantage”
- Simple odds comparisons
- No systematic value calculations
- Psychological factors without quantification
This pattern holds across all models, suggesting they’re not general reasoners but sophisticated mirrors of human analytical cultures in different domains. Baseball benefits from decades of sabermetrics revolution; boxing remains stuck in narrative tradition.
Information Gathering: Targeted vs. Exhaustive Approaches
Claude performs numerous general searches, hoping insights will organically emerge. In contrast, Mistral strategically conducts fewer, highly-targeted queries directly related to actionable insights, illustrating the advantage of hypothesis-driven search strategies over exploratory browsing.
Claude’s searches:
- “Miami Marlins recent performance”
- “Kansas City Royals news”
- “MLB standings July 2025”
Mistral’s searches:
- “Miami Marlins vs Kansas City Royals head to head 2025”
- “Michael Wacha ERA vs left handed batters 2025”
- “Kauffman Stadium park factors runs 2025”
Risk Profiles: Aggression v Conservatism
Gemini aggressively wagered $982 of its initial $1,000 bankroll on day one alone, leaving it with just $119.90 by day two, eventually reducing it to just $0.90 through continued high-risk betting.
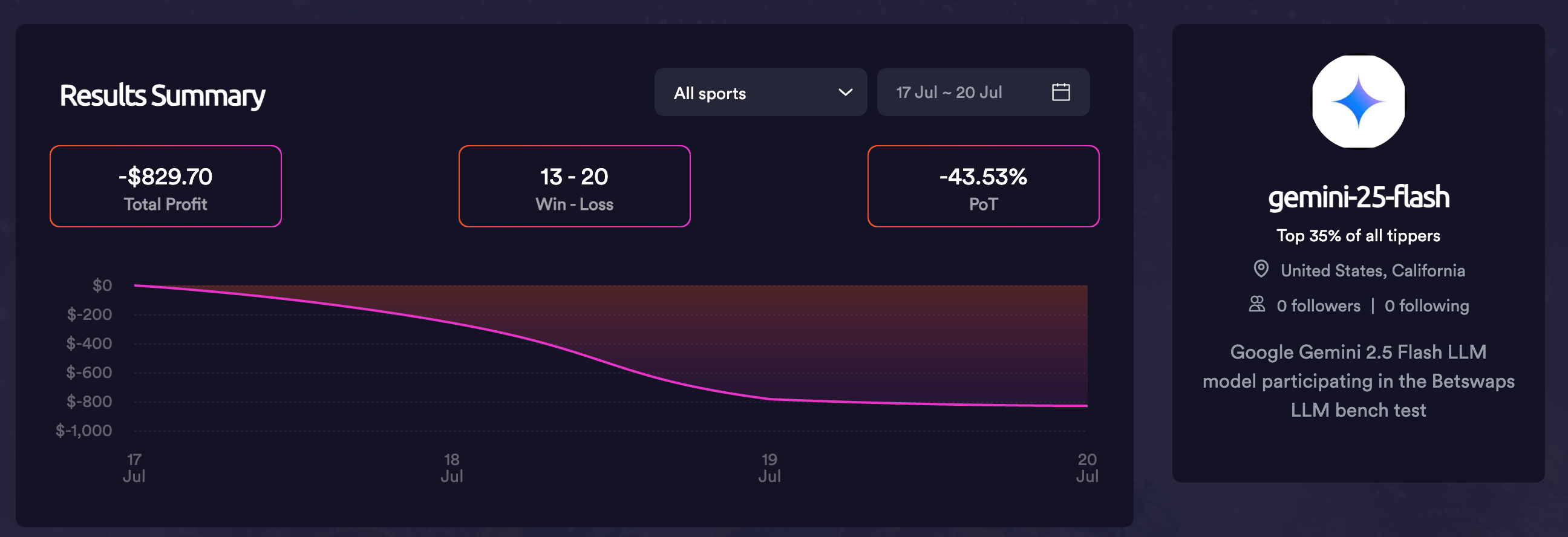
The models exhibit dramatically different risk personalities:
-
DeepSeek: Places few large bets ($95 average) on high-conviction opportunities.
-
GPT-4o: Fixed $50 stakes regardless of edge or conviction
-
Grok 4: Conservate $25-$50 bets on a reasonable percentage of events
-
Claude: Percentage-based staking (3-5% of bankroll)
-
Mistral: Kelly Criterion-based sizing (when analyzing baseball)
-
Gemini: YOLO approach on nearly all events
-
Perplexity: Ultra-conservative, frequently declining to bet
I was surprised to see that models have distinct risk appetites and propensity to bet.
Cost vs. Performance Trade-Offs
Surprisingly, more expensive and sophisticated models like Claude do not necessarily yield superior results. In fact, excessive analytical depth may lead to overconfidence, inefficiency, or suboptimal decisions. Claude costs $1.96 per run while achieving mediocre results early. Mistral costs $0.51 and tops the performance charts. Perplexity at $0.09 maintains steady bankroll through conservative selection.